Writing your first program in machine learning
Writing your first program in machine learning.
- Install
python. Download and install it from here -
Install
scikit-learnlibrary. For downloading and installation, follow the steps mentioned here. If you have installedAnaconda, thenscikit-learnis probably installed out of the box. You can directly go toSpydereditor (comes out of the box with Anaconda installation) and start with the program. Or else, you may choose any other IDE of your choice provided you have correctly installedscikit-learn. -
create a python file
hello_world.py. - Now, add the very first line of code in
hello_world.pywhich is to importscikit-learn. This would also validate if scikit-learn has been installed and configured correctly or not. Following is how content of filehello_world.pyshould look like now:import sklearn -
Run this program on the terminal or from any IDE of your choice. If the program executes successfully, it means
scikit-learn’s installation and import has been successful. - Next thing, we are going to do is, to import
treeclass fromscikit-learnlibrary. Following is the syntax for it:from sklearn import tree - Next, let us print some text to validate if everything is fine till now. Let us add a sample print line:
print("yay m born")
Since we are using supervised learning approach here, the first thing to have is training data. These are examples, of the problem we want to solve.
For our problem, we’re going to write a function to classify a piece of fruit that will take a description of the fruit as input, and predict whether it’s an apple or oranges. It would predict the output based on features like its weight and texture.
To collect our training data, imagine we head out to an orchard and look at different apples and oranges and start creating a table which describes their measurements. In machine learning world, we call these measurements as features.
To keep things simple, Let us have a look at the table below. We use two features. How much each fruit weighs and it’s texture which can be bumpy or smooth.
A good feature makes it easy to discriminate between different types of fruits. The last column is called the label. It identifies what type of fruit is in each row. The whole table is our training data.
What is happening in-turn is, our classifier will be trained on this data to identify outputs.
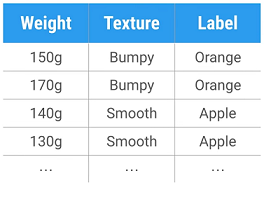
You can think of features as the inputs of the classifier and labels as the output. We would change the variable type of all our features to integers instead of strings,
hence we use 0 for bumpy and 1 for smooth. We do the same for our labels, so we use 0 for Apple and 1 for orange.
- Now let us add some lines in our program depicting the above logic like this:
# features 1 for smooth and 0 for bumpy , the first value is the weight, labels 0 for apple and 1 for orange
features = [[150, 0], [170, 0], [140, 1], [130, 1]]
labels = [0, 0, 1, 1]
- We would use Decision Tree Classifier in this program. For a detailed explanation about decision tree classifier, please read this link. This is how we initialize classifier. But remember, it is still an empty box of rules since it has not read any data.
clf = tree.DecisionTreeClassifier()
- Now, we would try to feed data to this classifier. Remember, we created two variables
featuresandlabels. These variables would be supplied to the classifier and classifier will read and understand the data to create a tree based decision model. Below is the code for that:
clf = clf.fit(features, labels)
- Next, we will supply a new test input and see how well the classifier predicts if it is an apple or orange:
print (clf.predict([[120,1]]))
- Now, our program is complete, the complete file looks like this:
import sklearn
from sklearn import tree
print("yay m born")
#features 1 for smooth and 0 for bumpy , the first value is the weight
#labels 0 for apple and 1 for orange
features = [[140, 1], [130, 1], [150, 0], [170, 0]]
labels = [0, 0, 1, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(features, labels)
print (clf.predict([[120,1]]))
- Upon running this program, following should be the expected output:
yay m born
[0]
This means, that the program has predicted the input as apple (0 denotes apple). This concludes our first program of supervised machine learning.
If you have any questions or feedback, please put your thoughts in the comments section below.
Happy learning !!